PyTorch Lightningで実装したPaDiMのソースコードを公開しました。本記事では、公開したソースコードの解説を行います。
1.本記事の目的
異常検知AIのPaDiMは論文発表から数年経っていますが、そのシンプルな考え方や、小さな欠陥に強い特徴などから、今でも使われています。
そんなPaDiMの実際の利用シーンですが、論文実装をそのまま使うというよりは、アプリケーションに合わせてカスタマイズして使うことが多いと思います。また、PyTorch Lightningで開発することがデファクトスタンダードになりつつある現状を踏まえると、ベースとなるプロジェクトとして、PyTorch Lightningで実装されたPaDiMがあるとカスタマイズに非常に便利そうです。
Webを調べてみると、ベースにできそうなものとしてAnomaLibのPaDiMの再実装があります。しかし、AnomaLibはPatchCoreなどの他のAIモデルとの共通化などの影響もあってか、リバースエンジニアリングするだけでも大変な苦労があり、私はカスタマイズ性は高くないと感じました。そこで、AnomaLibを参考にしつつ、カスタマイズしやすいようにシンプルな構成のPaDiMを再実装しました。
本記事の目的は、PyTorch Lightningで実装されたPaDiMの中身の解説を行い、本記事の読者さまがPaDiMを自由にカスタマイズできるようにすることです。
2.アーキテクチャ
ソースコードの解説の前にアーキテクチャを解説しておきます。先にここを理解しておくことで、全体像を把握することができ、よりソースコードの理解が深まるでしょう。
2.1.AIモデル部
プログラムの大まかな構成として、AIモデル部とデータローダー部の2つに分けられます。まずはAIの主要な動きを担当するAIモデル部を理解しておきましょう。
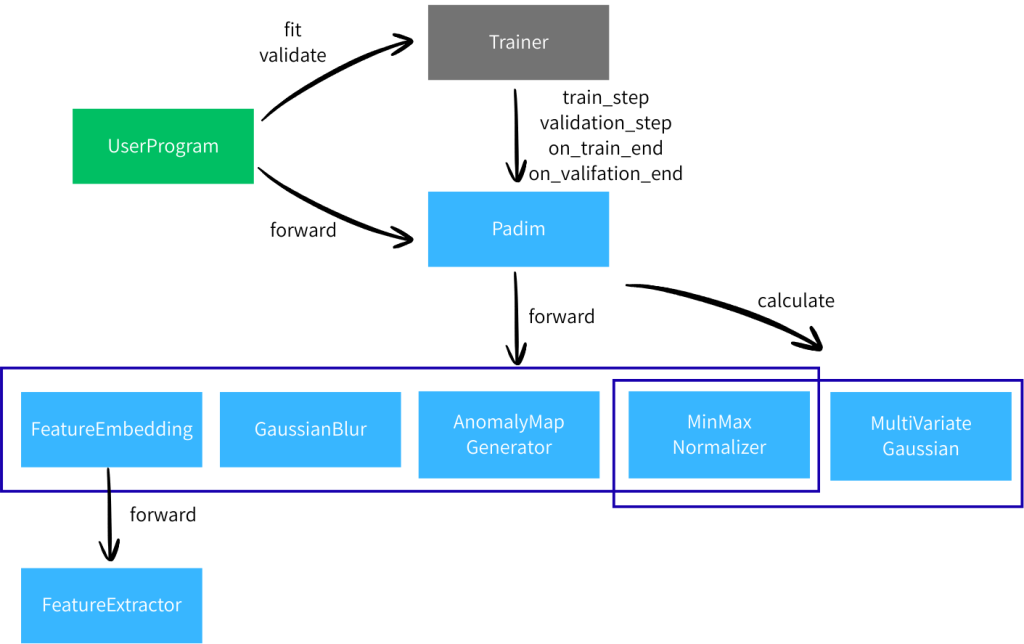
色分けの意味は以下の通りです。
- 水色:今回開発したクラス類
- 灰色:PyTorch Lightningのクラス
- 緑色:ユーザプログラム、今回は__main__.pyとします。
水色の部分について、順番に解説します。
2.1.1.Padim
Padimの全体をコントロールするクラスです。LightningModuleを継承しており、ここのソースコードを見るだけでも、おおよそ何をやっているか理解できると思います。
論文におけるPaDiMは、ざっくり特徴量抽出・マハラノビス距離計算・異常度マップ作成といった処理を行いますが、それらは全て別々のクラスとして実装し、このPadimクラスはそれらクラスを呼び出すだけの存在です。コントローラーやオーケストレーターと言うとわかりやすいかもしれません。
こうすることで、カスタマイズの際に、一部のクラスだけ改造したり、クラスを入れ替えたり、といったことをしやすくしています。
2.1.2.FeatureEmbedderとFeatureExtractor
FeatureEmbedderとFeatureExtractorで特徴量の抽出を行います。
FeatureExtractorは、シンプルにTimmを使って学習済みモデルで特徴量の抽出を行います。
FeatureEmbedderは、FeatureExtractorが抽出した特徴量の形状を合わせた後に、使用メモリ削減のために、特徴量のランダム抽出をする役割を持ちます。
2.1.3.MultiVariateGaussian
平均値と共分散行列を計算するクラスです。
学習完了時に、FeatureEmbedderにより抽出された特徴量を使い、平均値と共分散行列を計算します。
2.1.4.AnomalyMapGenerator
マハラノビス距離を計算し、異常度マップを生成するクラスです。
異常度マップ生成の際は、MultiVariateGaussianで計算した平均値と共分散行列を使用します。
2.1.5.GaussianBlur
異常度マップにぼかし効果を適用するクラスです。
2.1.6.MinMaxNormalizer
異常度マップを正規化するクラスです。
異常度マップはそのままだと扱いづらく、特にヒートマップ画像を生成する際に正規化されていないと困るので、0.0〜1.0に正規化します。正規化の方法は単純に最小値を0.0、最大値を1.0に正規化する方法を取りました。
どのデータの最小値・最大値を使うかについて、PadimCallbackのところでも触れましたが、検証データを使うこととし、Trainer.validation(…)の完了時に計算します。
2.2.データローダー部
主要部ではわかりやすさ重視でDataLoaderを省いて説明していました。Trainerは当然DataLoaderを使いますので、以下のクラスを用意します。
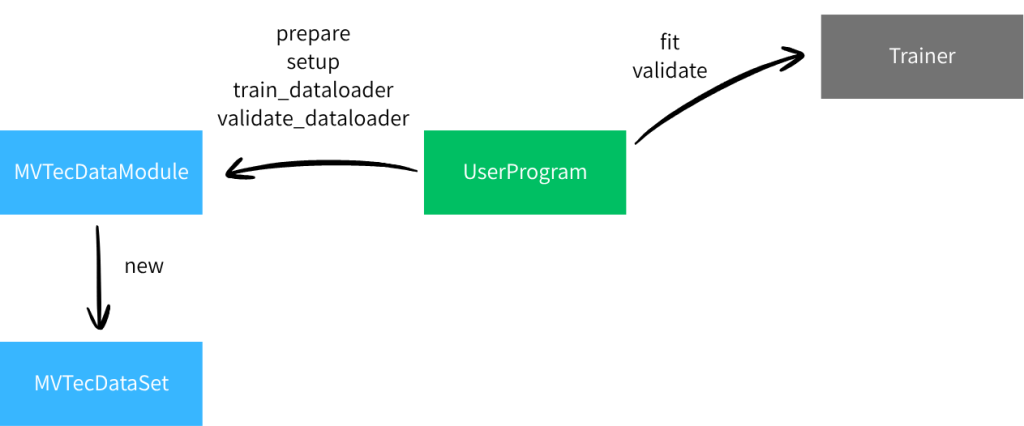
2.2.2.MVTecDataModule
MVTecの画像を利用するデータモジュールです。LightningDataModuleを継承し、以下のメソッドをオーバーライドしています。
- prepare
- Webから画像アーカイブのダウンロードを行います。
- setup
- train用のDataSetと、validation用のDataSetを生成します。
- DataSetの実装は後述するMVTecDataSetです。
- train_dataloader
- train用のDataLoaderを生成します。
- validation_dataloader
- validation用のDataLoaderを生成します。
2.2.1.MVTecDataSet
MVTecの画像用のDataSetです。単にMVTecの画像フォルダを参照し、DataSetとするクラスです。
3.ソースコード解説
すべてのソースコードの解説をしていると長くなりすぎてしまいますし、本記事の目的はカスタマイズできるようになることなので、ポイントを絞って解説していきます。
以下の順番に解説します。
- ユーザープログラム(__main__.py)
- Padim
- MultiVariateGaussian
ユーザープログラムが理解できれば、Padimモデルの使い方がわかるようになります。学習データの変更や、推論結果の加工といったカスタマイズができるようになります。
Padimが理解できれば、Padimモデルの中身の全体像がわかるようになります。AIモデル自体をカスタマイズしたい時に、どこを編集すれば良いのかわかるようになります。
基本的に上記2つを理解すれば十分ですが、MultiVariateGaussianだけ少し特殊な処理をしていますので、特別に解説します。
3.1.ユーザプログラム(__main__.py)
3.1.1.Transformの生成
まずはTransformを用意します。このTransformを学習データと推論データに共通して利用してください。やっていることは、Tensorに変換・サイズ変更・正規化です。
# Transform
transform = Compose(
[
ToImage(),
ToDtype(torch.float32, scale=True),
Resize(image_size, antialias=True),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
3.1.2.DataModuleの初期化
次にDataModuleを初期化します。
# LightningDataModule
data_module = MVTecDataModule(
data_dir=data_root,
target="bottle",
transform=transform,
batch_size=batch_size,
)
data_module.prepare_data()
3.1.3.Padimモデルの初期化
Padimモデルを初期化します。
# LightningModel
model = Padim(
backbone=backbone,
layers=layers,
n_features=n_features,
blur_sigma=blur_sigma,
)
backboneにバックボーンに使用するモデル名、layerysが特徴量抽出に使うブロック名の配列、n_featuresが使用する特徴量の数、blur_sigmaは異常度マップのぼかしに使うガウシアンぼかしのsigmaです。
3.1.4.学習
Trainerを初期化し、学習を実行します。
# Train
trainer = L.Trainer(max_epochs=1)
data_module.setup("fit")
trainer.fit(model=model, train_dataloaders=data_module.train_dataloader())
Trainer.fit(…)でtrain_dataloadersだけ指定しているため、学習は行われますが、検証は行われません。
学習が完了するとCallbackのon_train_end()が呼び出され、マハラノビス距離の計算に使用する平均値と共分散行列が計算されます。Callbackについては後ほど解説します。
3.1.5.検証
学習が終わったら、検証を実行します。
# Validation
data_module.setup("validate")
trainer.validate(model=model, dataloaders=data_module.val_dataloader())
検証が完了するとCallbackのon_validation_end()が呼び出され、異常度マップの正規化に使われる最小値・最大値が計算されます。Callbackについては後ほど解説します。
3.1.6.モデルの保存と読み込み
このステップは無くても構わないのですが、モデルの保存と読み込みのサンプルコードもあった方が良いと思って記載しておきました。
# Save the model
trainer.save_checkpoint(model_path)
# Load the model
model = Padim.load_from_checkpoint(
model_path,
backbone=backbone,
layers=layers,
n_features=n_features,
blur_sigma=blur_sigma,
)
モデルの保存はTrainerのsave_checkpoint()、モデルの読み込みはLightningModuleのload_from_checkpoint()を使います。load_from_checkpoint(…)の際に、初期化の引数が必要なので忘れないようにしてください。
3.1.7.推論
最後に推論を実行します。
# Read an image
image = cv2.imread(image_path)
input_tensor = transform(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
input_tensor = torch.unsqueeze(input_tensor, 0)
# Predict an image
model.eval()
anomaly_map = model(input_tensor)
# Print anomaly value
print(f"Anomaly value: {anomaly_map.max()}")
# Create and save the heatmap
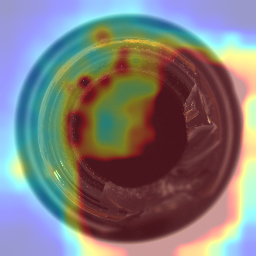
heatmap = superimpose_anomaly_map(anomaly_map, image)
cv2.imwrite("heatmap.png", heatmap)
画像の読み込みはOpenCVを使いました。OpenCVはBGRで読み込まれるので、RGBに変換した後に、Transformを適用しています。さらにテンソルの形状を合わせるためだけにtorh.unsqueeze(input_tensor, 0)をしています(バッチの分の次元を追加)。
推論の実行については、特筆する点はありません。
推論結果は2つの方法で出力しています。まずは、異常値をprintしており、これは論文通りに異常度マップの最大値としました。もう1つは異常度マップと元画像を合成したヒートマップ画像です。
3.2.Padim
前節ではAIモデルの使用方法を解説しました。ここではAIモデル本体であるPadimのソースコードの解説をします。
3.2.1.学習
まずは学習時の処理について解説します。
def training_step(self, batch, batch_idx):
embedding = self.feature_embedder(batch["image"])
self.embeddings.append(embedding)
学習時は、training_step()がバッチごとに呼び出されるので、ここでFeatureEmbedderを使って特徴量の抽出・収集を行います。FeatureEmbedderの中身は後述します。
学習が完了時すると、以下のコードを通ります。
def on_train_end(self) -> None:
# On training end, compute the MultiVariateGaussian parameters
embeddings = torch.vstack(self.embeddings)
self.gaussian.calculate(embeddings)
MultiValiateGaussian.calculate()を呼び出して、収集した特徴量から平均値と共分散行列を計算しておきます。これらは、異常度マップと生成する際に使用されます。
3.2.2.検証
次に、検証時の処理を解説します。
def validation_step(self, batch, batch_idx):
anomalymaps = self._generate_anomaly_map(batch["image"])
self.val_anomaly_maps.append(anomalymaps)
def _generate_anomaly_map(self, x: torch.Tensor, image_size=None) -> torch.Tensor:
# Generate embeddings
embeddings = self.feature_embedder(x)
# Compute anomaly map
anomaly_map = self.anomaly_map(
embeddings,
self.gaussian.mean,
self.gaussian.inv_covariance,
)
# Resize anomaly map to original image size if provided
if image_size is not None:
anomaly_map = F.interpolate(
anomaly_map,
size=image_size,
mode="bilinear",
align_corners=False,
)
# Apply Gaussian blur if specified
if self.blur is not None:
anomaly_map = self.blur(anomaly_map)
return anomaly_map
検証時は、バッチごとにvalidation_step()が呼び出されるので、ここで異常度マップの作成・収集を行います。
学習時では単に特徴量の抽出しか行っていませんでしたが、抽出した特徴量から異常度マップまで作成している点が異なります。
検証完了時には以下のコードを通ります。
def on_validation_end(self) -> None:
# On validation end, compute the MinMaxNormalizer parameters
val_anomalymaps = torch.vstack(self.val_anomaly_maps)
self.normalizer.calculate(val_anomalymaps)
収集した異常度マップを使って、異常度マップの最小値・最大値を計算します。この最小値・最大値は異常度マップの正規化のために使用します。
3.2.3.推論
最後に推論時の処理を見ていきましょう。
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Generate anomaly map
image_size = x.shape[-2:]
anomaly_map = self._generate_anomaly_map(x, image_size)
# Normalize the anomaly map
anomaly_map = self.normalizer(anomaly_map)
return anomaly_map
入力画像に対して、異常度マップを生成した後、正規化しているだけです。
3.3.MultiVaiateGaussian
3.3.1.モデル読み込み時
MultiVariateGaussianだけモデル読み込み時に特殊な処理をしているので、特別に解説します。
以下のソースコードを見てください。
def _load_from_state_dict(self, state_dict: dict, prefix: str, *args) -> None:
# # Resize the tensors in the state_dict to match the expected shapes
self.mean.resize_(state_dict[f"{prefix}mean"].shape)
self.inv_covariance.resize_(state_dict[f"{prefix}inv_covariance"].shape)
# Call the parent method to load the state_dict
super()._load_from_state_dict(state_dict, prefix, *args)
_load_from_state_dict(…)は、nn.Moduleのメソッドの1つで、モデル読み込み時に呼び出されます。
ここで行なっているのは、インスタンス変数のmeanとinv_covarianceのリサイズです。meanとinv_covarianceはそれぞれ、平均値と共分散行列です。
なぜリサイズが必要かというと、meanとinv_covarianceは、インスタンス初期化時の形状と、モデル読み込み時では形状が異なるためです。もし、リサイズを行わないとモデル読み込み時にエラーが発生してしまいます。
こうなってしまうのは、meanとinv_covarianceの形状は入力画像の形状に依存しているため、学習した後に形状が確定するからです。
そのため、モデル読み込み時に、読み込んだモデルの形状に合わせて、meanとinv_covarianceの形状を変更しているのです。
4.GitHub
最後に今回作成したソースコードのリンクを置いておきます。自由にカスタマイズしてください。
5.参考URL
- AnomaLib
- ソースコードは大いに参考にさせていただきました。
- 画像系異常検知モデルの仕組みについて調べてみた 2 – PaDiM編 –
- PaDiM自体の解説はここが大変参考になりました。